Collaborative Deep Learning
for Recommender Systems
Hao Wang
Naiyan Wang
Dit-Yan Yeung
Hong Kong University of Science and Technology
Massachusetts Institute of Technology
KDD 2015
Abstract
Collaborative filtering (CF) is a successful approach commonly used by many recommender systems. Conventional CF-based methods use the ratings given to items by users as the sole source of information for learning to make recommendation. However, the ratings are often very sparse in many applications, causing CF-based methods to degrade significantly in their recommendation performance. To address this sparsity problem, auxiliary information such as item content information may be utilized. Collaborative topic regression (CTR) is an appealing recent method taking this approach which tightly couples the two components that learn from two different sources of information. Nevertheless, the latent representation learned by CTR may not be very effective when the auxiliary information is very sparse. To address this problem, we generalize recently advances in deep learning from i.i.d. input to non-i.i.d. (CF-based) input and propose in this paper a hierarchical Bayesian model called collaborative deep learning (CDL), which jointly performs deep representation learning for the content information and collaborative filtering for the ratings (feedback) matrix. Extensive experiments on three real-world datasets from different domains show that CDL can significantly advance the state of the art.
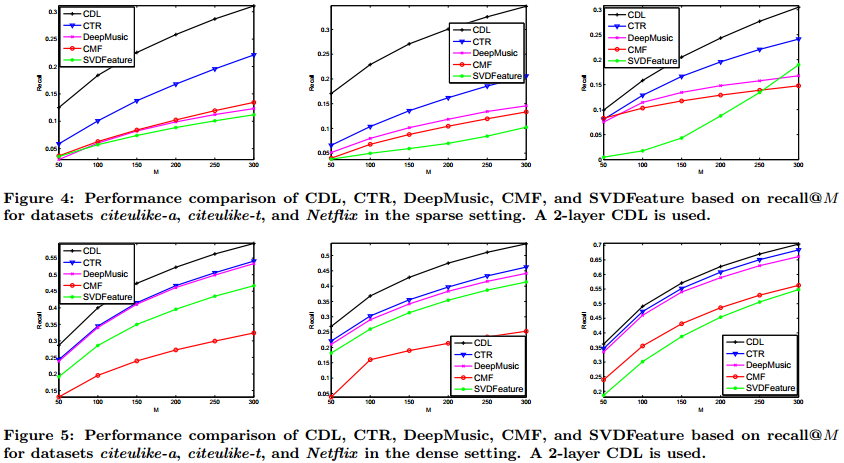
Quantitative Results
Below is the recall@M for different methods including our CDL. M is the number recommended items.
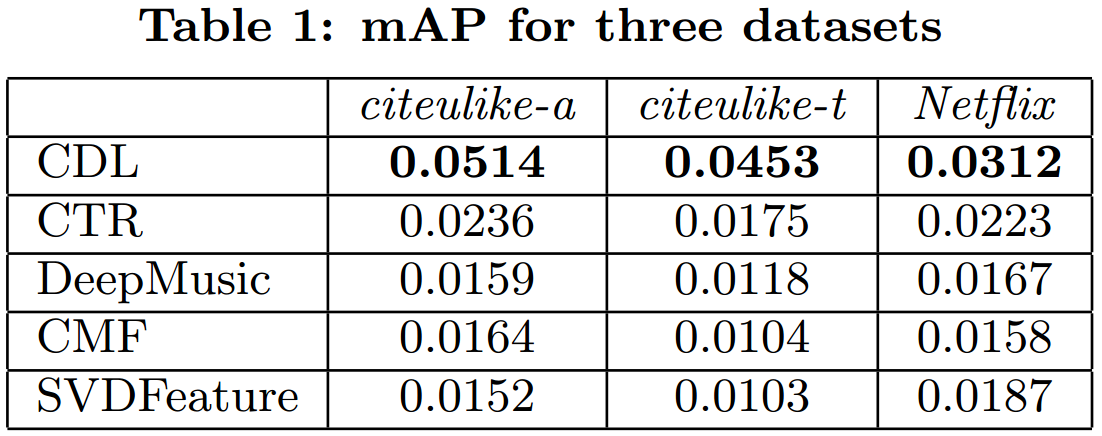
Here is the mean average precision (mAP) with the cut-off point set to 500.
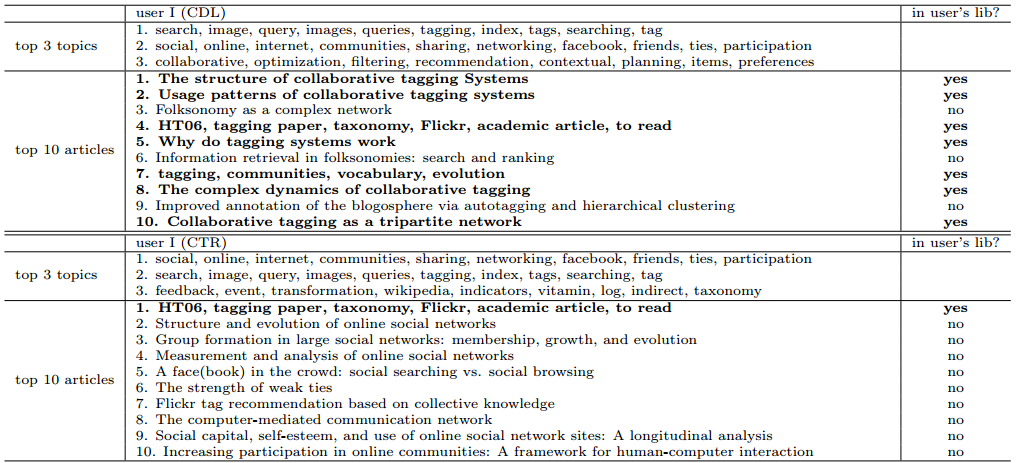
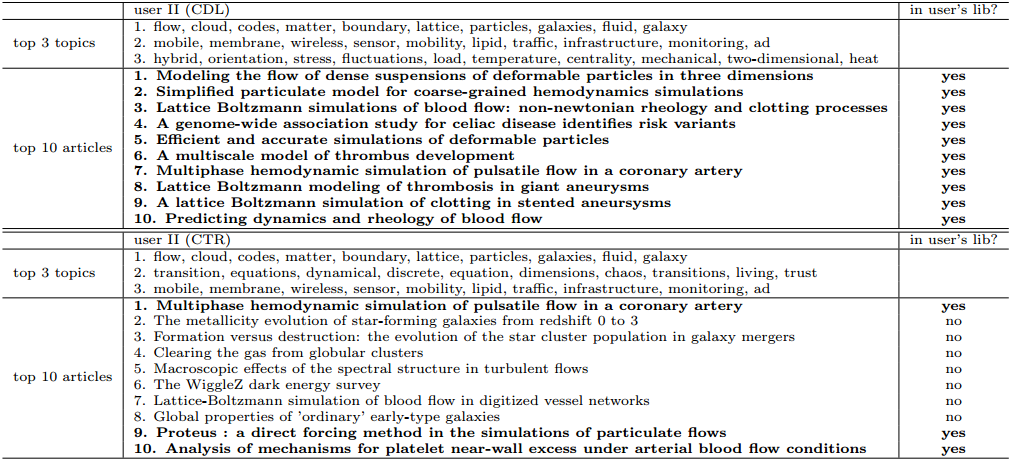
Qualitative Results
Interpretability and Accuracy
Below are two case studies where CDL and CTR recommend articles to User I and User II.
Sensitivity to Users' Interest Change and Accuracy
Below is a third case study where an example user (User III) 'watched' 10 movies one by one. During the process, CDL and CTR recommend movies to the user.
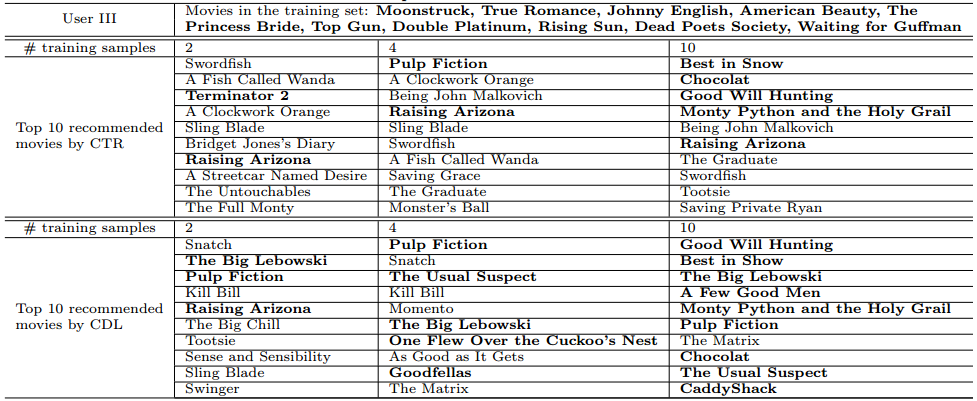
Movie 1 and Movie 2: The first 2 movies User III watched are 'Moonstruck' and 'True Romance', both of which are romance movies. Naturally, both CDL and CTR recommend some related romance movie to the user.
Movie 3 and Movie 4: The next 2 movies User III watched are 'Johnny English' and 'American Beauty'. These are drama and action movies, which are very different from the previous two. Note that this indicates a change of user interest. CDL sensitive enought to capture this change and recommend both romance and drama/action movies to User III, boosting the accuracy from 30% to 50%. However, CTR fails to do so and the accuracy remains 20%.
Other Movies: After User III watched and liked 10 movies, the accuracy of CDL's and CTR's recommendations is 50% and 90%, respectively.
Brief Model Introduction
In CDL, a probabilistic stacked denoising autoencoder (pSDAE) is connected to a regularized probabilistic matrix factorization (PMF) component to form a unified probabilistic graphical model.
Model training will alternate between pSDAE and regularized PMF. In each epoch, a pSDAE with a reconstruction target at the end and a regression target in the bottleneck will be udpated before updating the latent factors U and V in the regularized PMF.
Below is the graphical model for CDL. The part in the red rectangle is pSDAE and the rest is the PMF component regularized by pSDAE. Essentially, the updating will alternate between pSDAE (updating W and b) and the regularized PMF component (updating U and V).
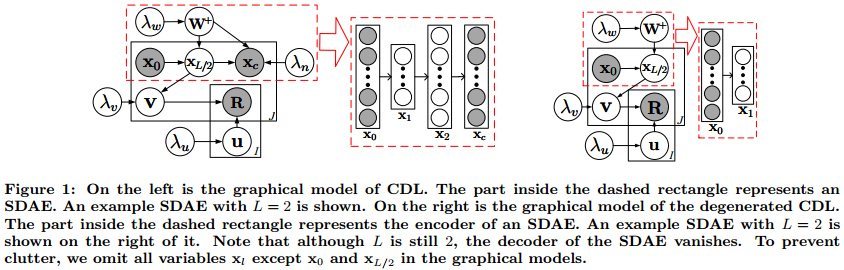
For more details on the notation, please refer to this page or the paper.
Code and Data
The code is available on Github or here, and the data is also available.
You can also check out our MXNet code for a simplied version of CDL on Github or here.
We also made a python notebook as part of the KDD 2016 MXNet tutorial, which is available on Github.
Other implementations (third-party):
Tensorflow code by gtshs2.
Another Tensorflow code by preferred.ai.
Keras code by zoujun123.
Python code by xiaoouzhang.
Acknowledgements
This research has been partially supported by research grant FSGRF14EG36.





